
Gamifying Data Science Education

00. Introduction
Part of the mission of Duo’s Data Science Team is to promote a data-driven culture. One way we do that is by running workshops that teach data science related skills. A recent workshop we developed aims to teach exploratory data analysis (EDA) in a gamified way. The session was conducted as a capture the flag (CTF) exercise, commonly used in the security community for security education. We’ll talk more about CTFs below. The workshop was very well received by participants, as evidenced by the following testimonials:
“The best CTF I’ve ever done” - Corporate security engineer
“Super fun and accessible to even basic folks like me!” - Product designer
“Thanks so much this is such a fun puzzle activity” - Software engineer
Some participants liked it so much they kept capturing flags after the session ended!
One of Duo’s core values is “learning together.” An event that exemplifies this value is the annual internal tech conference open to anyone in the R&D department, which includes teams like Engineering, Security, and Product Management. We’ve had this conference since 2018. In the first year the data science team led sessions teaching Apache Spark and data visualization. This recent year we led a workshop to teach exploratory data analysis (EDA).
01. Exploratory Data Analysis
Data analysis skills are becoming increasingly useful as more and more roles require answering questions with data. For example, as an engineer, you might want to understand how a code change will impact performance. As a security operator, you might care about trends regarding browser usage and application access. As a product designer, you might want to build hypotheses on how UI changes affect user behavior. If you’re lucky enough to have a dataset that can answer your questions, you’ll need to know how to make sense of the data.
The first step a data analyst or scientist takes when given a new dataset is usually EDA. EDA is an iterative process for learning and making sense of a dataset. During EDA, you progressively reduce the complexity of your dataset through a cycle of:
- Asking questions
- Looking for answers in the data
- Using your insights to refine your questions or generate new ones
The EDA cycle illustrated by this graphic:
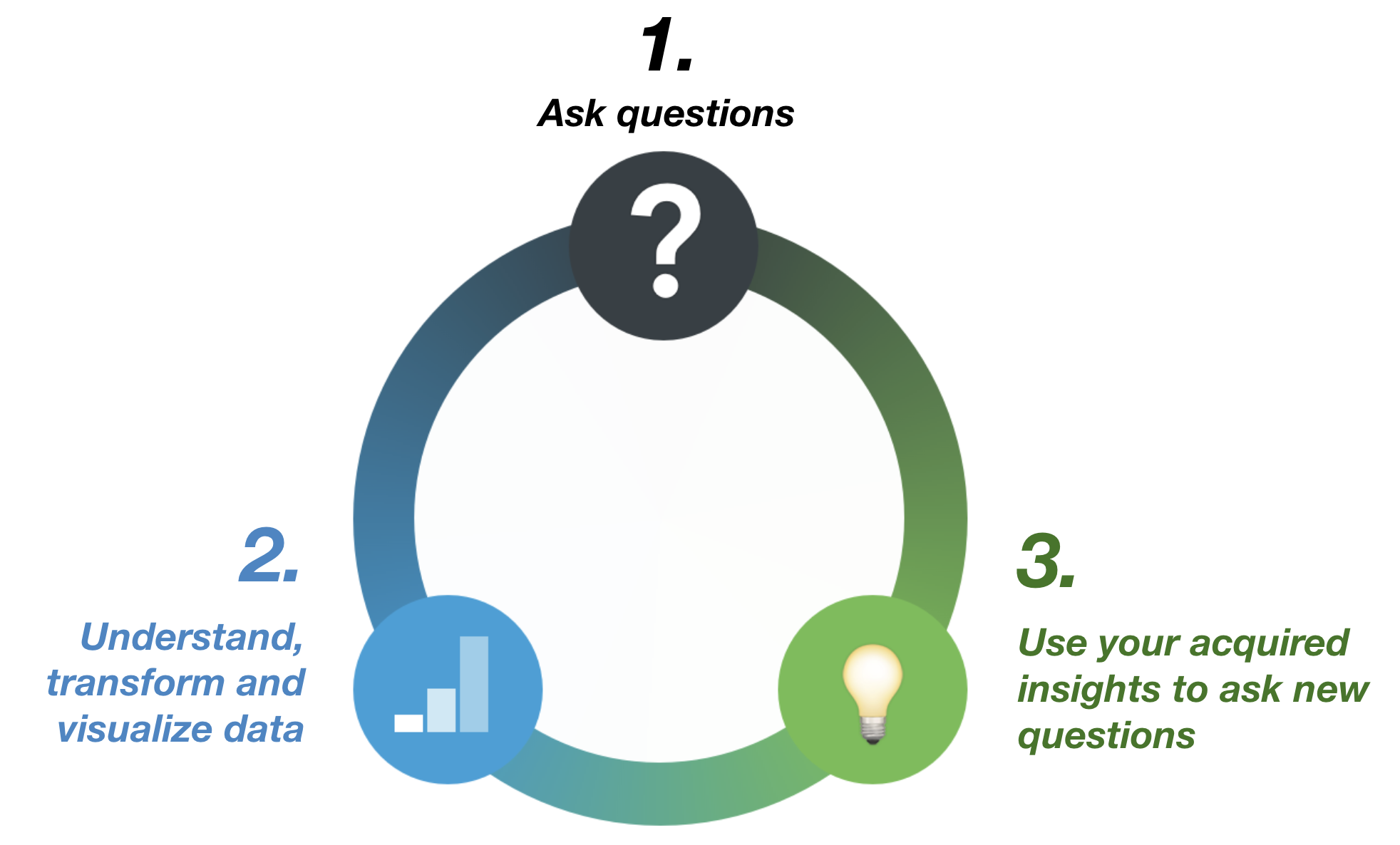 EDA iterative cycle
EDA iterative cycle
One of the best ways to learn EDA is through answering questions with data, and that’s the focus of our workshop.
02. What is a CTF?
In the security community a CTF is usually a competition where participants are tasked with solving information security challenges. There is usually a web-based platform that provides challenges and when the participant provides the correct answer they are rewarded a “flag” worth a certain number of points. The participant or team with the most points by the end of the competition wins. CTFs are usually used as teaching tools or as competitions at conferences.
At Duo, the application security team uses CTFs to teach application security concepts. Their excellent CTF workshops inspired us to do something similar for data science. We liked the gamification and interactivity CTFs bring and wanted to incorporate that into our workshops.
03. How the Data Science CTF Works
To bring the gamification of security CTFs to data science, we built a CTF around data analysis challenges. In order to create challenges we need data to analyze. We found or created 6 datasets, then created data analysis challenges for each one. Challenges might require the participant to find summary statistics, create visualizations, or transform the data in different ways in order to answer the question. Some challenges unlock other challenges when solved, leading the participant to deeper insights about the data. Point values for capturing each flag corresponds to difficulty level.
We decided the challenges must be solvable in a spreadsheet environment to allow a wide audience to learn about EDA. As a result, all the challenges can be completed in Google Sheets, but participants can use any data analysis environment, such as Python in a Jupyter notebook and RStudio.
At a high level these are the datasets we used:
- 200M Sprint: Olympic race times for the track and field event “200M Women”. Each challenge comes with guided instruction, and are based on tutorials we sent out prior to the session. The dataset is meant as a warm-up to the other challenges.
- Movie Ratings: fictional dataset of movie ratings. Created to illustrate Simpson’s paradox.
- Challenge Death: Coroner’s inquests from 18th century Westminster, taken from here.
- Jeopardy: Game results from Jeopardy! Episodes, gathered from j-archive.com
- Two datasets based on Duo’s authentication logs. Challenges are related to users, 2nd factor authentication methods, and policies. We’d like to make it clear that we did not use customer data for these challenges, and all user information was anonymized.
To see the datasets and challenges check out the Github repo. Datasets related to Duo’s authentication logs are not included.
The scoring server we used is CTFd. It’s an easy to use open-source platform for CTFs. CTFd provides the ability to create challenges, group participants into teams, and show team progress via a scoreboard. Challenges are hosted on the server and grouped by dataset. The flag for each challenge is the answer to the question.
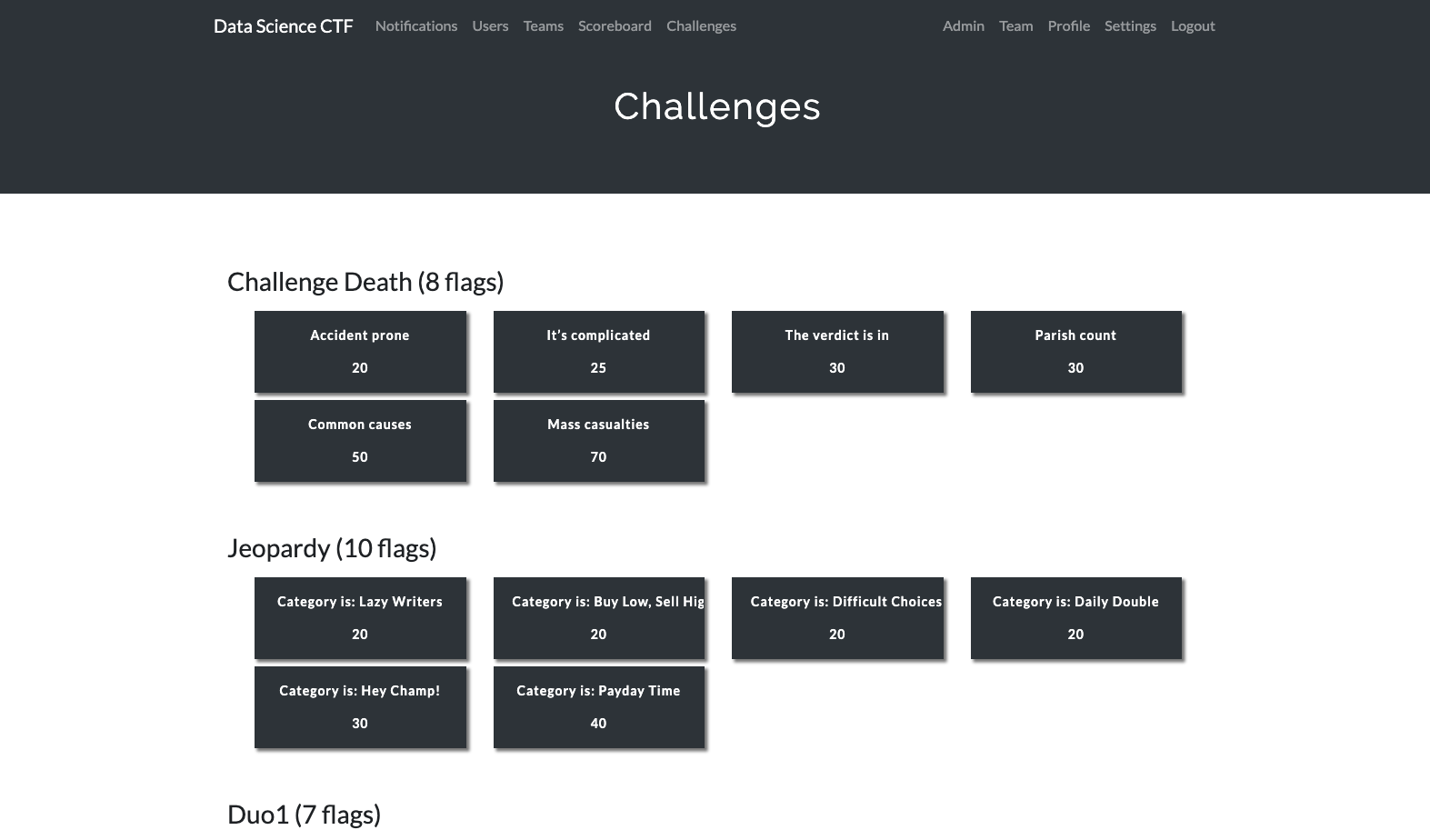 Screenshot: Challenges page on the CTFd scoring server
Screenshot: Challenges page on the CTFd scoring server
Challenge Example
The Jeopardy dataset is a good example of what the challenges teach participants. Each row contains data on a Jeopardy! question from a historical game. The data includes information on: the position of the question on the board, the number of attempts to solve the question, the point value of the question, whether the question is a Daily Double etc.
Daily Doubles are special questions scattered throughout the board that let a contestant wager an amount and either win double that amount (if answered correctly) or lose that amount. Some of the CTF challenges ask what row the Daily Double is most frequently on, and whether Daily Doubles are harder than regular questions on that row.
A series of challenges lead the participant to the insight: some positions of the board have questions that are easier to answer relative to the point value. Consequently, there are various strategies with greater odds of winning that one can glean from historical games.
04. Running the Session
A week before the session we sent out preparation materials which included tutorials on how to use Google Sheets and Pandas in Python. The tutorials provide step-by-step instruction for answering challenges related to the 200M sprint dataset. We asked participants to complete the tutorials before the workshop. The tutorials were crucial to ensuring participants spent the session solving challenges instead of setting up their environment or learning basic analysis operations. Including the tutorial questions as CTF challenges made it easy for participants to learn the platform quickly.
At the beginning of the session the data science team did a 20 minute presentation on the role of EDA in data science, EDA best practices, and how the CTF works. Then we split participants into teams of 3-4 people and had them solve challenges. During the session the data science team went around the room to answer questions.
05. Session Results
The session was very well received. Encouraged by positive reviews, we ran the workshop again in October for security awareness month. Teaching EDA in the form of a CTF created an amazing level of engagement. In fact, a number of participants asked for the platform to stay running so they could solve challenges after the session. Some people actually did, as evidenced by the scoreboard:
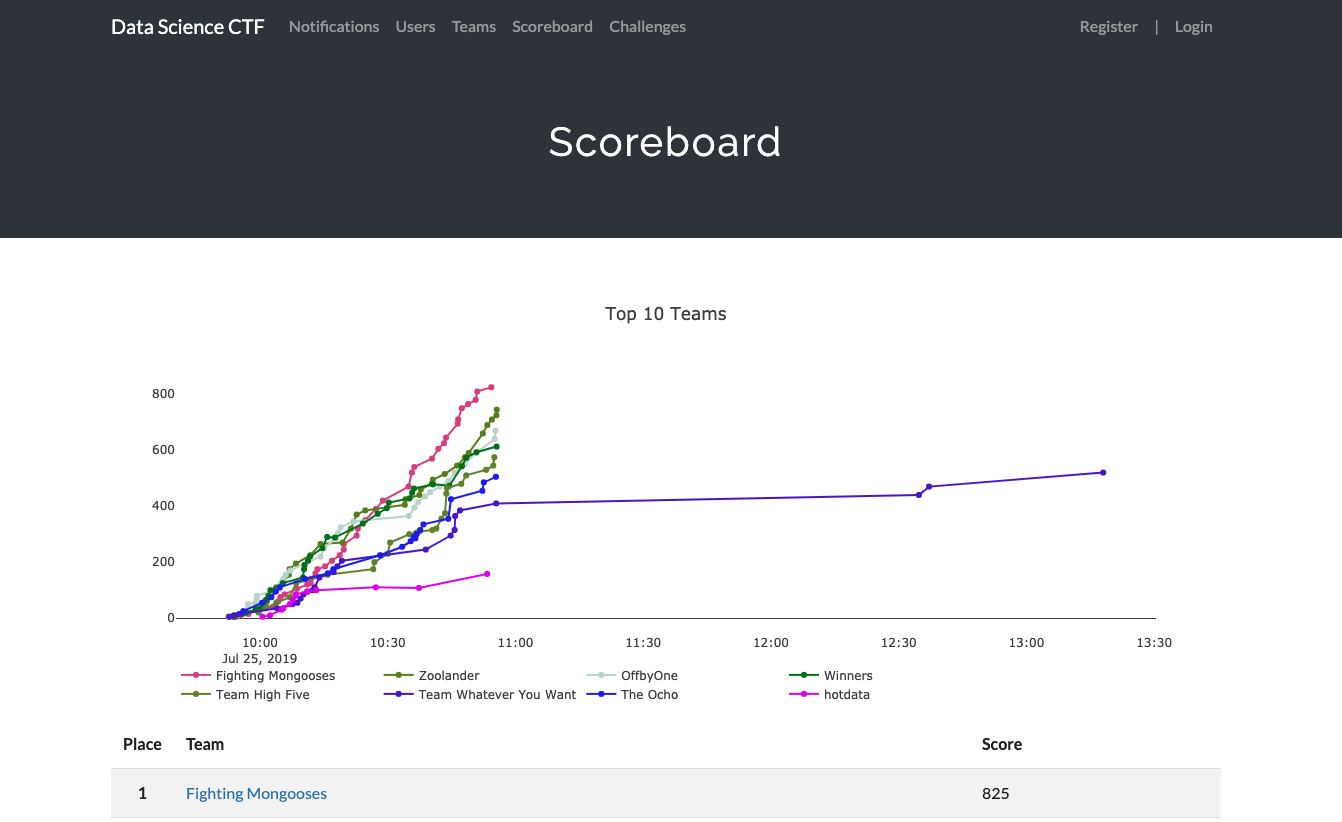 Screenshot: scoreboard from tech conference session
Screenshot: scoreboard from tech conference session
The plot shows team score by time, with one line per team. All lines end at 11am, which is when our session ended, but some on team “Team Whatever You Want” kept solving challenges until after noon.
Some other interesting facts:
- Jeopardy and Challenge Death were the most popular datasets. We defined popular as the number of unique users who attempted challenges in that category. These datasets may be popular because they’re real-world, complex datasets participants don’t encounter in their day-to-day work, not to mention Jeopardy and coroner’s records are interesting topics.
- The participant with the highest score by a large margin was one of Duo’s summer interns.
- After we ran the session a second time, we sent out a survey. Most participants thought challenge difficulty was just right. A few thought it was too hard or too easy.
06. Lessons Learned
Like any workshop there is room for improvement. During the first session, we discovered participants had issues with flags that require more complex input formatting. For example a challenge asked for sequences of dates and events, ordered by date and separated by semicolons. A nice feature of CTFd is you can specify regex flags, so we adjusted the flag to be more lenient towards white space and delimiters. We also adjusted minor issues around challenge clarity.
The scoring platform CTFd is a great platform, but there are improvements we’d like to make to customize it to our needs. Some are:
- More flexible challenge answers. We limited the number of challenges asking for visualizations because the platform didn’t have built-in support for that type of flag.
- Better reporting, such as: showing the team score normalized by the number of people in the team, showing the first team to complete a category of challenges etc.
Another issue is some participants with a stronger data analysis background found the challenges a little too easy. We could create datasets and challenges that are explicitly labelled as more difficult to cater to that audience. To encourage the “exploratory” part of EDA, we could create challenges around more open ended questions.
The second time we ran the CTF, the event featured a largely remote audience. Most teams managed to be successful by coordinating over Slack. On the other hand there seemed to be less collaboration among teammates compared to the in-person session.
07. How You Can Run a Data Science CTF
We’ve open sourced much of the CTF content in hopes that other organizations will run similar workshops. Some suggested steps to get started with running your CTF:
- Host CTFd so it’s accessible by participants.
- Use the datasets and challenges in our repo to create flags. Optionally create new datasets and challenges using your organization’s data or publicly available datasets.
- A week before the session, send out the preparation materials to participants. The materials are everything in the repo except for the documents with the analysis challenges and the template slides.
- Start the session off with a presentation on EDA. You can customize these template slides. Let participants loose on the challenges!
08. Conclusion
Gamifying data analysis education resulted in a fruitful workshop. By combining CTFs traditionally used in information security with data analysis, members of the R&D department were able to learn data analysis skills in an engaging and exciting way.
Although we talked about EDA in this post, the CTF idea can be extended to other content. If catering to an audience familiar with machine learning, you could create challenges around ML models. We hope to see other organizations run similar workshops and build on the CTF concept!